Content from Introduction
Last updated on 2025-11-10 | Edit this page
Overview
Questions
- What is RNA-seq and what kind of biological questions can it answer?
- What is a “counts table” and why is it central to RNA-seq data analysis?
- Why are biological replicates essential for meaningful statistical analysis?
- How can we organize RNA-seq count data in R for downstream analysis?
- What preliminary steps and R packages are needed to begin a DE analysis?
Objectives
- Describe the overall workflow of RNA-seq from sequencing to count tables.
- Explain the difference between biological and technical replicates and their impact on analysis.
- Identify the key components of an RNA-seq count table.
- Load and inspect RNA-seq data in R.
- Organize data into a DGEList and prepare accompanying sample information.
- Load the R packages needed for RNA-seq differential expression analysis.
Introduction
Comparing gene expression, i.e. the amount of RNA transcript, in different experimental conditions provides important biological insights. For example, comparing gene expression in cancer and non-cancer tissue gives us insights into the biology of cancer. While there are many ways of measuring gene expression, the focus of this workshop will be (bulk) RNA-seq, a technology which (nominally) measures gene expression across the whole transcriptome, i.e. all RNA transcripts, in a sample.
The main aim of this workshop is to show you how to go from a “counts table” of RNA-seq data to a ranked list of differentially expressed (DE) genes using R and statistical software packages from Bioconductor (note: basic knowledge of R will be assumed). This aim may seem modest, but our approach will be to carefully discuss each step along the way. The motivation for this is twofold: (1) to give you some understanding and thus confidence in what you’re doing; and (2) to give you some skills to judge whether the DE results you obtain are likely to be trustworthy or rubbish.
The second motivation is important. In our context, rubbish DE results take two forms: missed discoveries (i.e. failing to infer a gene to be DE when it really is DE) or false discoveries (i.e. inferring a gene to be DE when it’s actually not DE). Rubbish results are a real danger in the following way: you can competently do all the steps in this workshop and still arrive at rubbish! How is this possible? Because some data sets aren’t amenable to the kinds of analyses we’ll be discussing, and it’s important to know when this occurs (if you care about the results!). Such data sets are typically problematic or difficult in some way and will require techniques and strategies beyond those contained in this workshop to obtain non-rubbish results. The good news, however, is that many data sets are amenable to the analyses we’ll discuss.
Our starting point for RNA-seq analysis will be a table of counts; we won’t begin from raw sequencing data (in the form of .fastq files). There’s several reasons for this:
Firstly, going from raw sequencing data to a table of counts can be computationally intensive and a little involved.
Secondly, because of this, workshops often fail to spend enough time on the (more important) statistical part that comes after this, ie. analysing the table of counts.
Thirdly, many people have no interest in processing raw sequencing data; they’re simply interested in analysing one of vast number of publicly available counts tables of RNA-seq data. If you’ve generated raw sequencing data of your own (or want to look at publicly available raw sequencing files) then you should look at other workshops for how to go from this data to a table of counts*. But, if you’ve got a table of counts that you want to analyse, then this is the workshop for you!
*The nf-core/rnaseq pipeline may be a good starting point if that is your goal.
Some background
RNA-seq involves several steps, as summarised in this figure:
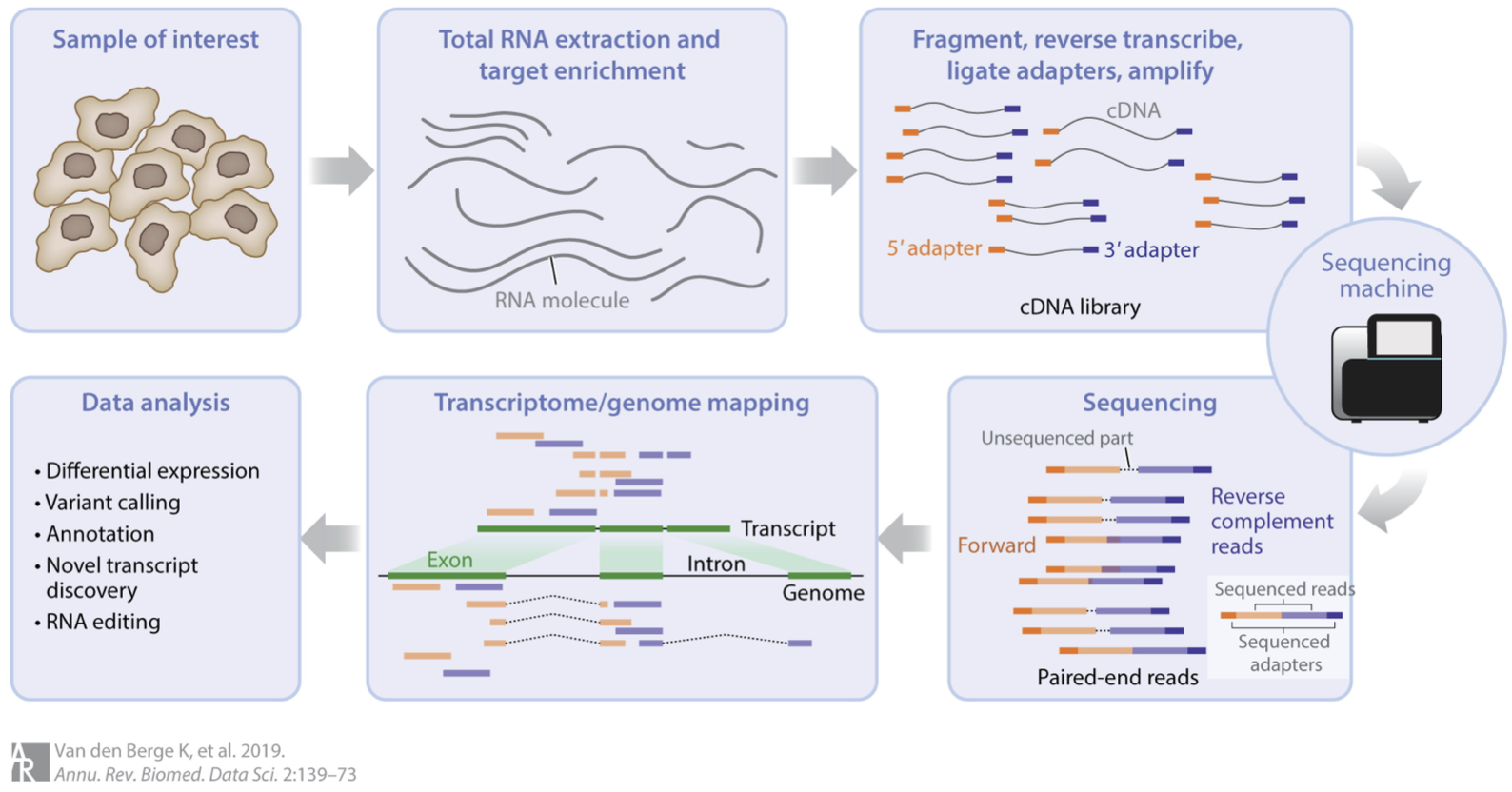
We could say a lot more about each step, but this isn’t our focus. For us, the important thing to know is that after this whole process we arrive at a table of counts—the fundamental object of RNA-seq data analysis. For example, here’s a made up table of counts for two groups (A and B) each with three biological replicates (using the typical ‘genes rows, samples in columns’ convention):
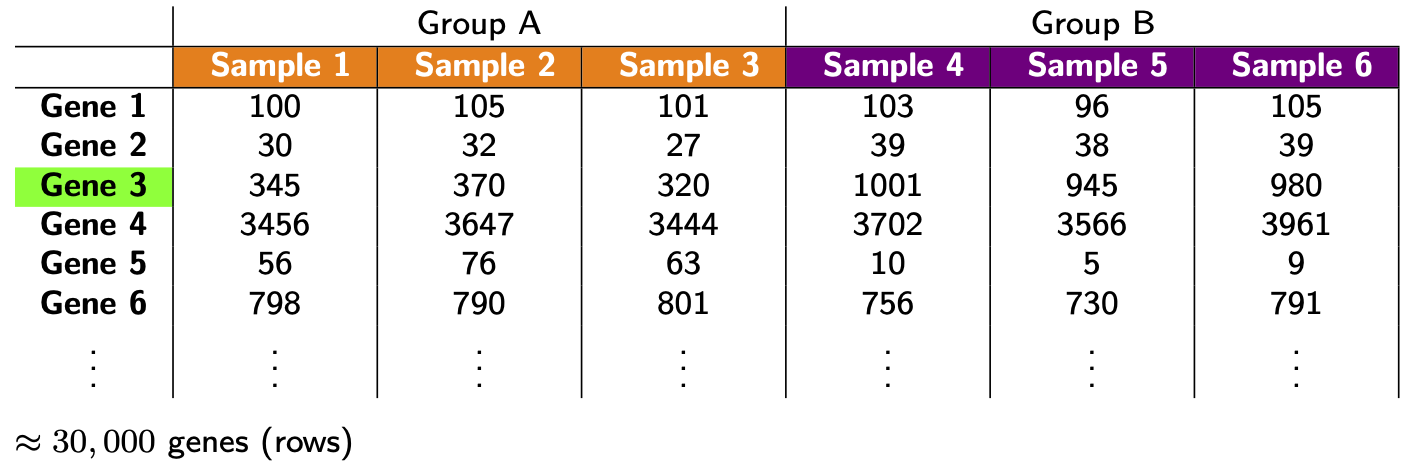
The counts quantify expression: more counts, more expression (roughly speaking—see below). The fundamental question we want to ask is: which genes are DE between the groups? (e.g. is Gene 3 DE?)
Before proceeding, some important comments about replicates:
- If you don’t have replicates (ideally for all groups), STOP! You’ll likely produce rubbish results (actually statistical tools will often give you an error in this situation, but not always!). Here “replicates” means biological replicates (data collected from distinct individuals), not technical replicates (data repeatedly collected from the same individual), a distinction nicely depicted in the figure below. Biological replicates are essential because you cannot do rigorous RNA-seq analysis (i.e. statistics) without them. Why? There are many reasons, e.g. you’ll have no way of estimating the (biological) variation, i.e. “noise”, in your data and so no way of properly comparing any “signal” (of DE) to the “noise” (actually there are some ways around this issue but they’re not recommended). Thus, 2 replicates is a minimum and 3+ replicates (depending on the context and situation) are recommended.
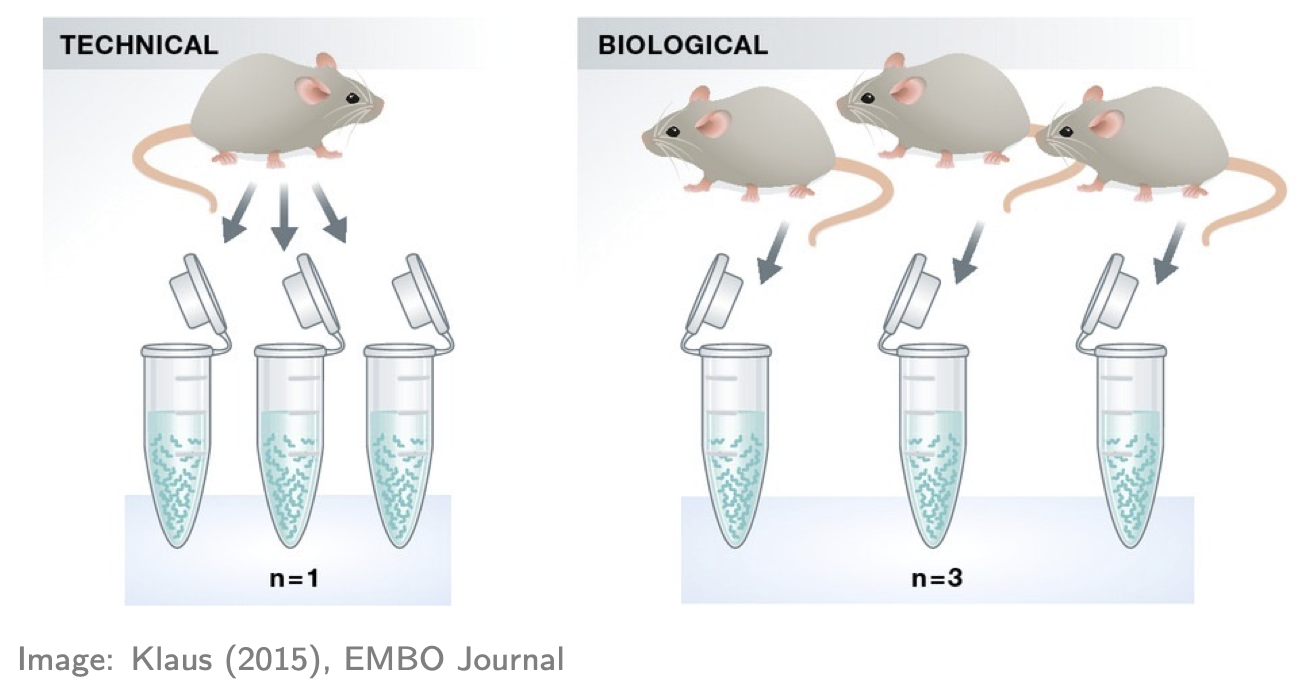
- If you have technical replicates, PROCEED CAREFULLY! They shouldn’t be analysed as if they were separate (independent) samples. Why? To see the main reason, consider an example: suppose one of your groups consists of three individuals each with 2 technical replications, making 3x2 = 6 samples in that group. It may seem like there’s 6 samples in that group for doing the relevant statistics, but don’t be fooled: there’s only 3 independent samples (i.e. distinct individuals). If you analysed the 6 samples as if they were separate samples, your analysis would “overestimate” the amount of information available—there’s only 3 “pieces” of information, not 6—and thus might produce many false discoveries (because the estimated variation might be too small). The standard advice for handling technical replicates is this: add the counts (gene-wise) of each technical replicate to produce single biological replicates. Note, however, that this only applies if there’s no significant technical differences between the replicates (e.g. the technical replicates sit almost on top of each other in a PCA plot—see below). If there are significant technical differences between the replicates (e.g. if each replicate is in different batch, which incidentally is one of the main reasons for generating technical replicates) then you should consult an expert. And, if you’re in doubt about applying this advice, consult an expert!
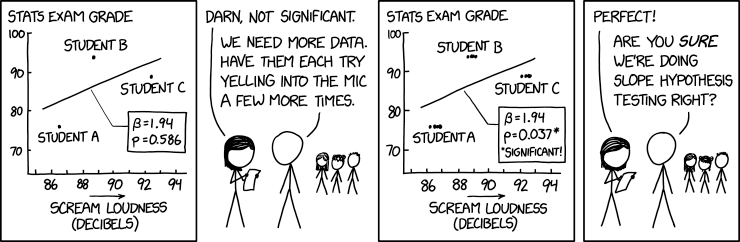
Another nice way of understanding the technical replicate issue above is through humour, e.g. reflect on the mistake being made in this xkcd comic:
Example data
For illustration, we’ll look at data from the publication: Obers et al. “Retinoic acid and TGF-β orchestrate organ-specific programs of tissue residency”, Immunity (2024). The aim of this study was to investigate the roles of retinoic acid (RA) and the cytokine TGFb in driving organ-specificity of tissue resident T cells.
The relevant RNA-seq counts table for this study can be obtained from Gene Expression Omnibus as follows:
- Use this link
- Scroll down to the “Supplementary file” section
- For the file “GSE232852_CountsTable.txt.gz” (first row), hit “ftp” or “http” in the “Downloads” column
Once the file is downloaded, move it to your R working directory and unzip it. Now let’s read it into R and take a look (note: you’ll need to adjust the file path accordingly):
R
tab <- read.table("data/GSE232852_CountsTable.txt", header=TRUE)
head(tab, n=50)
OUTPUT
EnsemblID Symbol RA_1 RA_2 RA_3 TGFb_1 TGFb_2 TGFb_3
1 ENSMUSG00000102693 4933401J01Rik 0 0 0 0 0 0
2 ENSMUSG00000064842 Gm26206 0 0 0 0 0 0
3 ENSMUSG00000051951 Xkr4 0 0 0 0 0 0
4 ENSMUSG00000102851 Gm18956 0 0 0 0 0 0
5 ENSMUSG00000103377 Gm37180 0 0 0 0 0 0
6 ENSMUSG00000104017 Gm37363 0 0 0 0 0 0
7 ENSMUSG00000103025 Gm37686 0 0 0 0 0 0
8 ENSMUSG00000089699 Gm1992 0 0 0 0 0 0
9 ENSMUSG00000103201 Gm37329 0 0 0 0 0 0
10 ENSMUSG00000103147 Gm7341 0 0 0 0 0 0
11 ENSMUSG00000103161 Gm38148 0 0 0 0 0 0
12 ENSMUSG00000102331 Gm19938 0 0 0 0 0 0
13 ENSMUSG00000102348 Gm10568 0 0 0 0 0 0
14 ENSMUSG00000102592 Gm38385 0 0 0 0 0 0
15 ENSMUSG00000088333 Gm27396 0 0 0 0 0 0
16 ENSMUSG00000102343 Gm37381 0 0 0 0 0 0
17 ENSMUSG00000102948 Gm6101 0 0 0 0 0 0
18 ENSMUSG00000025900 Rp1 0 0 0 0 0 0
19 ENSMUSG00000104123 Gm37483 0 0 0 0 0 0
20 ENSMUSG00000025902 Sox17 0 0 0 0 0 0
21 ENSMUSG00000104238 Gm37587 0 0 0 0 0 0
22 ENSMUSG00000102269 Gm7357 2 0 1 0 0 0
23 ENSMUSG00000096126 Gm22307 0 0 0 0 0 0
24 ENSMUSG00000103003 Gm38076 0 0 0 0 0 0
25 ENSMUSG00000104328 Gm37323 0 0 0 0 0 0
26 ENSMUSG00000102735 Gm7369 0 0 0 0 0 0
27 ENSMUSG00000098104 Gm6085 16 30 10 16 14 10
28 ENSMUSG00000102175 Gm6119 0 2 1 1 3 0
29 ENSMUSG00000088000 Gm25493 0 0 0 0 0 0
30 ENSMUSG00000103265 Gm2053 0 0 0 1 1 1
31 ENSMUSG00000103922 Gm6123 10 11 6 2 5 4
32 ENSMUSG00000033845 Mrpl15 948 1158 880 940 880 943
33 ENSMUSG00000102275 Gm37144 9 21 19 12 4 6
34 ENSMUSG00000025903 Lypla1 609 711 577 752 688 647
35 ENSMUSG00000104217 Gm37988 1 3 1 0 3 2
36 ENSMUSG00000033813 Tcea1 1289 1617 1252 1427 1270 1216
37 ENSMUSG00000062588 Gm6104 1 2 2 2 3 3
38 ENSMUSG00000103280 Gm37277 0 0 0 0 0 0
39 ENSMUSG00000002459 Rgs20 0 0 0 2 0 0
40 ENSMUSG00000091305 Gm17100 0 0 0 0 0 0
41 ENSMUSG00000102653 Gm37079 0 0 0 0 0 0
42 ENSMUSG00000085623 Gm16041 0 0 0 0 0 0
43 ENSMUSG00000091665 Gm17101 0 0 0 0 0 0
44 ENSMUSG00000033793 Atp6v1h 873 1047 756 1110 1024 1009
45 ENSMUSG00000104352 Gm7182 0 0 0 0 0 0
46 ENSMUSG00000104046 Gm37567 0 0 0 0 0 0
47 ENSMUSG00000102907 Gm38264 0 0 0 0 0 0
48 ENSMUSG00000025905 Oprk1 0 0 0 0 0 0
49 ENSMUSG00000103936 Gm36965 0 0 0 0 0 0
50 ENSMUSG00000093015 Gm22463 0 0 0 0 0 0
RA_TGFb_1 RA_TGFb_2 RA_TGFb_3 WT_1 WT_2 WT_3
1 0 0 0 0 0 0
2 0 0 0 0 0 0
3 0 0 0 0 0 0
4 0 0 0 0 0 0
5 0 0 0 0 0 0
6 0 0 0 0 0 0
7 0 0 0 0 0 0
8 0 0 0 0 0 0
9 0 0 0 0 0 0
10 0 0 0 0 0 0
11 0 0 0 0 0 0
12 0 0 0 0 0 0
13 0 0 0 0 0 0
14 0 0 0 0 0 0
15 0 0 0 0 0 0
16 0 0 0 0 0 0
17 0 0 0 0 0 0
18 0 0 0 0 0 0
19 0 0 0 0 0 0
20 0 0 0 0 0 0
21 0 0 0 0 0 0
22 1 0 1 0 0 0
23 0 0 0 0 0 0
24 0 0 0 0 0 0
25 0 0 0 0 0 0
26 0 0 0 0 0 0
27 12 14 16 9 15 19
28 3 4 2 0 0 2
29 0 0 0 0 0 0
30 0 1 0 0 0 0
31 7 9 7 5 4 11
32 656 1197 944 1123 967 1375
33 17 17 18 12 9 24
34 476 837 688 717 709 846
35 0 3 0 0 1 2
36 993 1666 1440 1563 1445 1878
37 2 1 1 5 0 7
38 0 0 0 0 0 0
39 0 0 0 0 0 0
40 0 0 0 0 0 0
41 0 0 0 0 0 0
42 0 0 0 0 0 0
43 0 0 0 0 0 0
44 819 1417 1144 1101 973 1347
45 0 0 0 0 0 0
46 0 0 0 0 0 0
47 0 0 0 0 0 0
48 0 0 0 0 0 0
49 0 0 0 0 0 0
50 0 0 0 0 0 0Here’s what we have:
- The first 2 columns are gene annotation: “EnsembleID” and “Symbol”, respectively (note: EnsembleID is one of many standard gene identifiers in use; anther common identifier is “Entrez” gene ID).
- The next 12 columns represent the count data on the four experimental groups of interest, each with three biological replicates; specially, a special kind of T cell treated with either: RA, TGFb, both (RA_TGFb), or neither (WT).
Preliminaries
Before we can start analysing this data, there’s four preliminaries:
- Let’s load the R packages we’ll be using (note: if you don’t have the relevant packages installed, then you’ll need to run the commented code):
R
# # CRAN packages
# install.packages(c("ggplot2","ggrepel","ggfortify","scales","pheatmap","matrixStats","openxlsx"))
library(ggplot2)
library(ggrepel)
library(ggfortify)
library(scales)
library(pheatmap)
library(matrixStats)
library(openxlsx)
# # Bioconductor packages
# install.packages("BiocManager")
# BiocManager::install(c("limma","edgeR"))
library(limma)
library(edgeR)
We’ll mainly be using limma and some functions from
edgeR to analyse the data above; the other packages will be
used for plotting and exporting results tables.
- We need to organize our data into
DGEListwhich is a special “container” for our analysis:
R
annotation <- tab[,c(1,2)]
counts <- tab[,-c(1,2)]
dge <- DGEList(counts=counts, genes=annotation)
Note that we split the data table into two distinct parts—gene annotation and counts—storing each into the relevant slots of the container.
- It’s helpful to create a table of sample information:
R
samples <- colnames(tab)[-c(1,2)]
group <- c(rep("RA",3), rep("TGFb",3), rep("RA_TGFb",3), rep("WT",3))
info <- data.frame(samples, group)
info
OUTPUT
samples group
1 RA_1 RA
2 RA_2 RA
3 RA_3 RA
4 TGFb_1 TGFb
5 TGFb_2 TGFb
6 TGFb_3 TGFb
7 RA_TGFb_1 RA_TGFb
8 RA_TGFb_2 RA_TGFb
9 RA_TGFb_3 RA_TGFb
10 WT_1 WT
11 WT_2 WT
12 WT_3 WTHere the first column is a unique sample name and the second labels the experimental group the sample belongs to. Incidentally, this would be the place to store any other relevant sample information (e.g. what batch each sample belongs to, if relevant) and even relevant biological covariates (e.g. sex, age, etc.). Note also that such sample information is usually prepared separately (in, say, Excel) and then read into R; since our example is simple, we created it on the fly.
- We need to create a factor vector for our groups:
R
group <- factor(info$group)
group
OUTPUT
[1] RA RA RA TGFb TGFb TGFb RA_TGFb RA_TGFb RA_TGFb
[10] WT WT WT
Levels: RA RA_TGFb TGFb WTFactor vectors are special in R: they have an extra piece of
information called “levels” (in this case, it’s saying this factor has
four levels), information which R uses to specify statistical models
etc. As you’ll see, this particular group vector will be
important in our analysis.
- RNA-seq measures gene expression across the transcriptome, producing count data per gene per sample.
- The main goal of DE analysis is to identify genes with expression differences between conditions.
- Biological replicates are required for valid statistical inference; technical replicates must be combined or carefully handled.
- A “counts table” is the starting point for most RNA-seq analyses in R.
- Preparing a DGEList object and sample metadata correctly is essential for downstream analyses with limma and edgeR.
- Understanding the data structure and design factors early helps ensure trustworthy DE results later.
Content from First steps: filtering, visualisation, and basic normalisation
Last updated on 2025-11-10 | Edit this page
Overview
Questions
- Why should we filter out genes with little or no expression before differential expression analysis?
- What does “library size” mean, and why is it important to check?
- How can visualisation help us detect technical variation in RNA-seq data?
- What are the main sources of technical variation in RNA-seq experiments?
- How and why do we normalise RNA-seq data?
- What are CPM and TMM, and how do they help make samples comparable?
- How can we assess whether normalisation has worked correctly?
Objectives
- Filter out lowly expressed genes to reduce noise and improve statistical power.
- Inspect and interpret library sizes to identify potential problems.
- Create and interpret PCA, boxplot, and RLE visualisations to assess technical variation.
- Explain the difference between biological and technical variation in RNA-seq data.
- Perform basic normalisation to correct for library size and compositional differences.
- Evaluate whether normalisation has successfully reduced unwanted technical variation.
- Recognise when batch effects or other confounding factors may require more advanced correction methods.
Filtering
So, assuming your counts table has biological replicates in each
group (and any technical replicates have been taken care of), the first
thing we need to do is filtering. More precisely, removing
genes with little to no expression, because the former add “noise” while
the latter aren’t even relevant. There are various approaches to
filtering, but one of the simplest is to use the limma
function filterByExpression:
R
keep <- filterByExpr(dge, group=group) # logical vector indicating which rows of dge to keep
table(keep) # 32069 genes will be removed; 14009 genes will be kept
OUTPUT
keep
FALSE TRUE
32069 14009 R
dge <- dge[keep,,keep.lib.size=FALSE]
head(dge$counts) # compare to pre-filtered data to see the difference
OUTPUT
RA_1 RA_2 RA_3 TGFb_1 TGFb_2 TGFb_3 RA_TGFb_1 RA_TGFb_2 RA_TGFb_3 WT_1 WT_2
27 16 30 10 16 14 10 12 14 16 9 15
32 948 1158 880 940 880 943 656 1197 944 1123 967
33 9 21 19 12 4 6 17 17 18 12 9
34 609 711 577 752 688 647 476 837 688 717 709
36 1289 1617 1252 1427 1270 1216 993 1666 1440 1563 1445
44 873 1047 756 1110 1024 1009 819 1417 1144 1101 973
WT_3
27 19
32 1375
33 24
34 846
36 1878
44 1347Roughly speaking, this strategy keeps genes that have a reasonable number of counts in a worthwhile number samples, and removes them otherwise (see function help for precise details).
Following filtering, you should check the library size of each sample. The library size of a sample is simply the sum of the counts in that library, i.e. \[ \begin{align*} \text{Library size for sample}\ j &= \sum_{i} Y_{ij} \\ & = \sum_{\substack{\text{all genes}}} \text{counts for sample}\ j \end{align*} \] where \(Y_{ij}\) is the count for gene \(i\) in sample \(j\). Here’s a plot of the library sizes for our data:
R
lib.size.millons <- colSums(dge$counts) / 1e6
barplot(lib.size.millons, las=2, cex.names=0.8, main="Library size (millons)")
abline(h=20, lwd=2, col="red2")
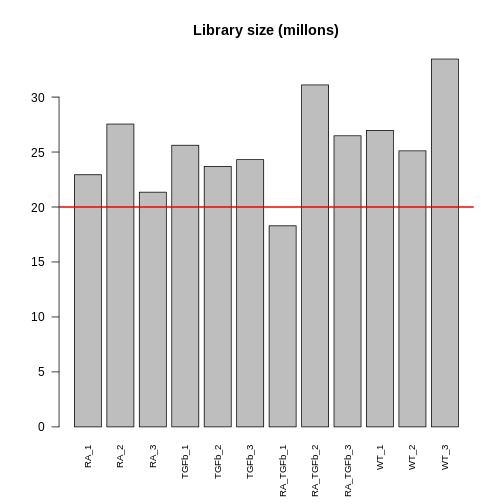
Library size is an important quantity. One reason to check it is because bigger is usually better: 5 million or less (not that good); 10-15 million (better); 20+ million (much better). This is because (1) it’s a limited resource that needs to be “shared” between all the genes (in proportion to their expression); and (2) bigger counts generally means better statistical properties (e.g. power to detect DE). Another reason to check is because it will help signpost what tools you should use to analyse your data (more about this later).
Visualisation
The next thing to do is visualise your data. This allows you to (1) see the landscape of biological differences between experimental groups, and (2) assess whether the data is affected by technical variation. Detecting technical variation is particularly important because its presence leads to missed and/or false discoveries, i.e. rubbish DE results. Thus, this step is crucial: analysing RNA-seq data without visualisation is literally “flying blind”!
There are many visualisation methods. Each has different advantages and show different aspects of the data—there is no single perfect visualisation, so use several! Here we’ll discuss three:
PCA plots. These give a special low dimensional representation of our (very) high dimensional data (i.e. where we’ve taken thousands of measurements on each sample). A ``good” plot looks like this: (1) replicates cluster; and (2) there’s some separation of biological groups.
Boxplots. These are very simple: you take all the expression measurements in each sample and dump them into a boxplot, one boxplot for each sample. A ``good” set of plots looks like this: the boxplots are lined up, without much movement between them.
RLE plots. These are the same as boxplots but with one extra (crucial) step: subtracting the row median from each row before dumping the observations into boxplots. This additional step removes the between-gene variation, making the plot more sensitive than boxplots for detecting technical variation. A ``good” plot looks like this: the boxplot medians are lined up around zero and the boxes are roughly the same size.
If any of these plots don’t look ``good”, in the ways described, this indicates the presence of technical variation.
Let’s make each plot then discuss them:
R
# log transform counts, note: 1/2 offset to avoid log transforming zeros
y <- log2(dge$counts + 1/2)
# PCA plot (nice ggplot version, potentially for publication)
pca <- prcomp(t(y), center=TRUE)
autoplot(pca, data.frame(group=group), col='group', size=4) +
theme_classic() +
ggtitle("PCA plot")
WARNING
Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
ℹ Please use tidy evaluation idioms with `aes()`.
ℹ See also `vignette("ggplot2-in-packages")` for more information.
ℹ The deprecated feature was likely used in the ggfortify package.
Please report the issue at <https://github.com/sinhrks/ggfortify/issues>.
This warning is displayed once every 8 hours.
Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
generated.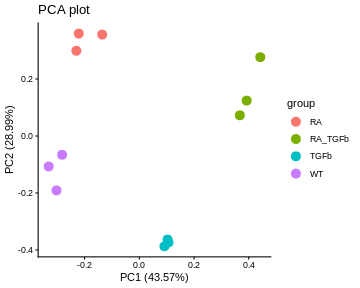
R
# boxplot and RLE plot (simple base R versions; they're generally not for publication)
par(mfcol=c(1,2))
cols.group <- group
levels(cols.group) <- hue_pal()(4)
boxplot(y, col=as.character(cols.group), outline=FALSE, las=2, cex.axis=0.6, main="Boxplots")
RLE <- y - rowMedians(y)
boxplot(RLE, col=as.character(cols.group), outline=FALSE, las=2, cex.axis=0.6, main="RLE plot")
abline(h=0, col="grey20", lwd=3, lty=1)
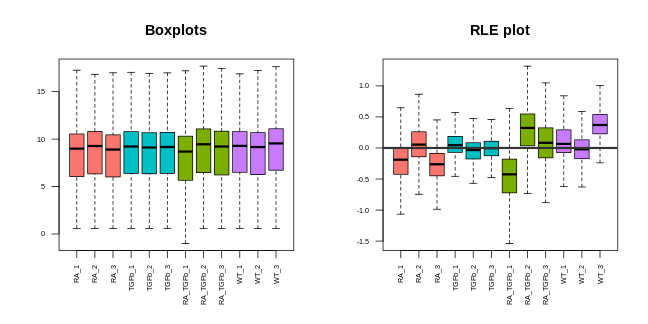
Note that we made these plots with log transformed counts, not the counts themselves (the reason for this is technical: the log transformation roughly removes the strong mean-variance relationship inherent in RNA-seq data, something we don’t want driving our visualisations).
For our data, the PCA plot looks okay; the replicates cluster reasonably well and there’s separation of biological groups. The boxplots and RLE plot, on the other hand, tell a different story (which is why you should visualise your data multiple ways!). The boxplots are wobbling around a little, which is a problem. Indeed, the RLE plot reveals things are far from ideal. The boxplots and RLE plot clearly indicate the presence of technical variation which needs to be removed if we’re to obtain non-rubbish results. This is the topic we turn to next.
Basic normalisation
Unfortunately, when doing RNA-seq analysis we can’t simply compare counts between samples because there’s almost always technical differences between them. To make samples properly comparable, the data needs to be normalised: we need to remove or adjust for technical differences between samples, leaving only biological differences (the thing we’re interested in!). Failing to successfully normalise your data can lead to significant missed and/or false discoveries (rubbish results).
Two important technical differences between samples are (1) library size differences and (2) compositional differences:
- Library size differences. To see the problem here look at Gene 3 in the made up table of counts:
Does Gene 3 show a biological or technical difference between the two groups? Looks like a biological difference, but what if I told you the library sizes for group B were 3 times bigger? In that case, the difference looks more like an artifact of library size rather than a true biological difference. Let’s look at the problem another way:
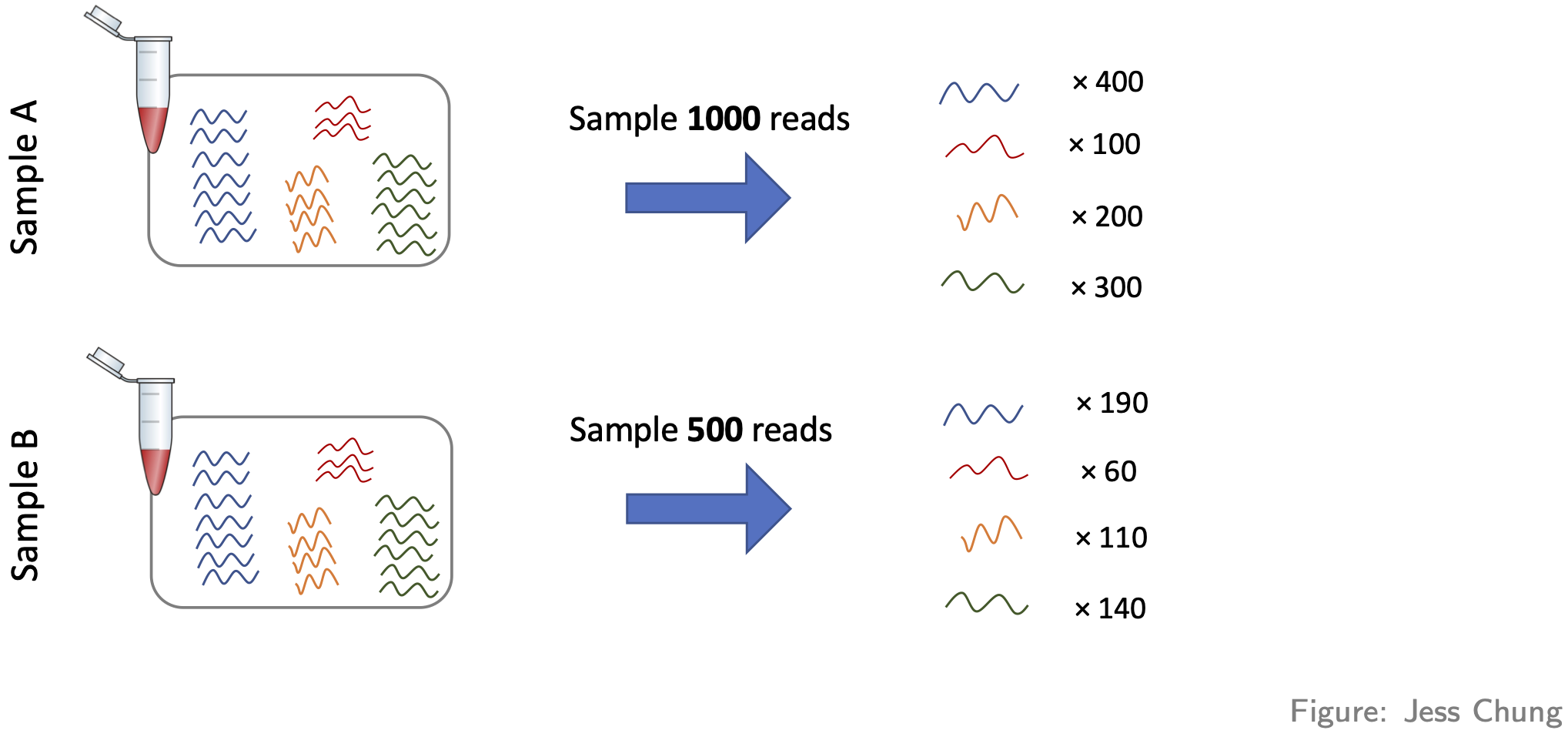
It should be clear from this that differences resulting from different library sizes can be mistaken for biological differences. One simple way to (roughly) normalise for library size differences is to calculate counts-per-million (CPM). If we again let \(Y_{ij}\) be the count for gene \(i\) in sample \(j\), and let \(N_j\) be the library size for sample \(j\), then the CPM value for gene \(i\) in sample \(j\) is given by \[ \text{CPM}_{ij} = \frac{Y_{ij}}{N_j} \times 10^6 = \frac{\text{Count}}{\text{Library size}} \times 10^6, \] Because CPM values are (scaled) proportions, i.e. “Count / Library size”, not absolute counts, the issue of library size differences is no longer relevant.
- Compositional differences. For each sample, the probability of sequencing a transcript is proportional to its abundance—this is the basis of how RNA-seq works (of course!). To see the potential problem this fact creates, look at this figure:
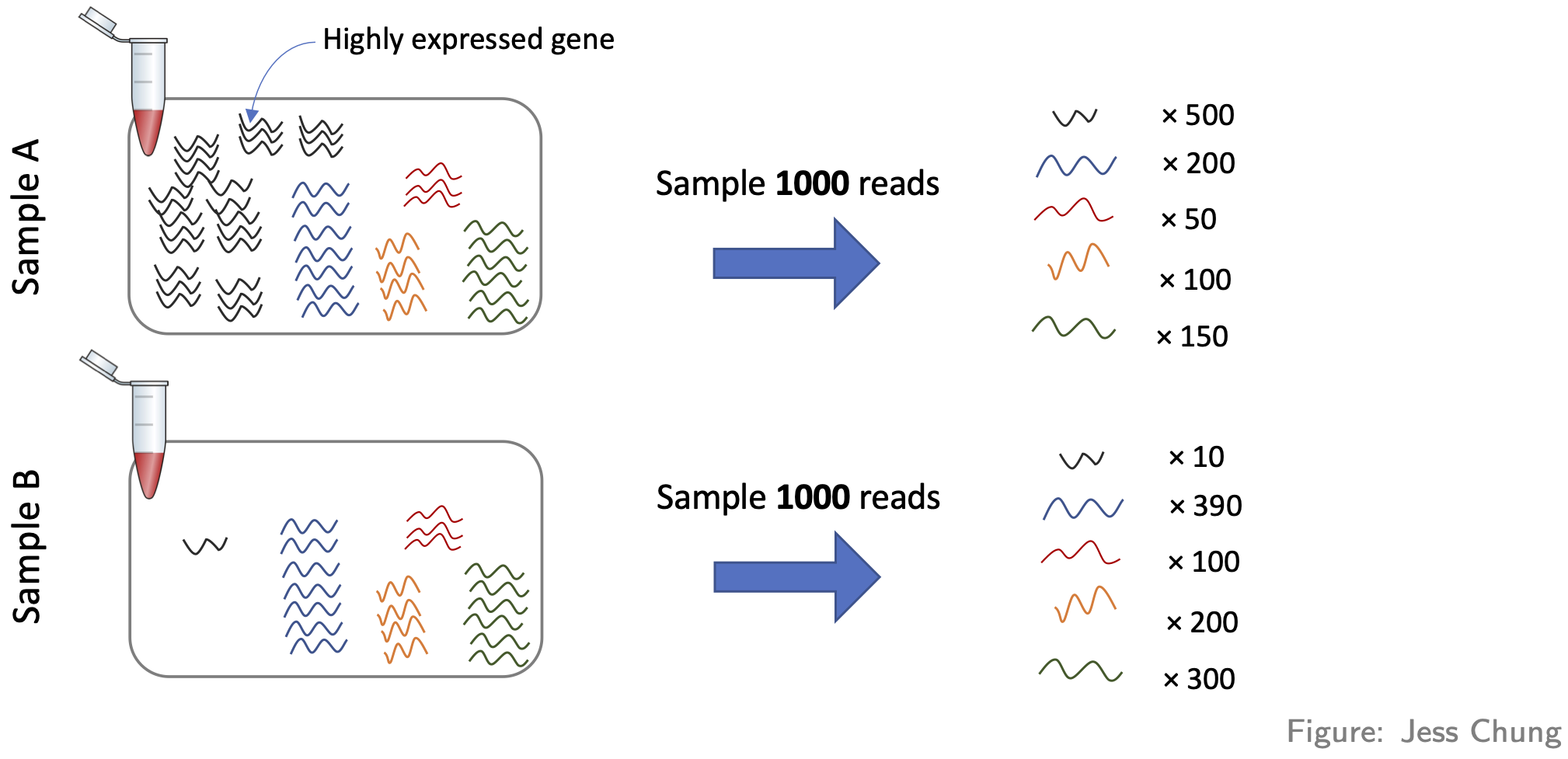
These two samples are the same (they have the same number of red,
yellow, blue, and green transcripts) except for the black transcript:
sample A has many more black transcripts. This difference in composition
means that even if the library sizes are the same, comparing raw counts
still gives the wrong impression. One popular approach for normalising
out these differences is the TMM method (from the
edgeR package).
Here’s how to adjust for library size and compositional differences in our example:
R
dge <- calcNormFactors(dge, method="TMM") # adjustment factors for composition; stored in our container for later use
CPM <- cpm(dge) # adjustment factors for composition incorporated when calculating cpm values
head(CPM) # compare to the raw counts
OUTPUT
RA_1 RA_2 RA_3 TGFb_1 TGFb_2 TGFb_3 RA_TGFb_1 RA_TGFb_2 RA_TGFb_3
27 0.728 1.13 0.476 0.613 0.576 0.40 0.635 0.439 0.589
32 43.136 43.55 41.866 36.001 36.189 37.76 34.720 37.554 34.726
33 0.410 0.79 0.904 0.460 0.164 0.24 0.900 0.533 0.662
34 27.711 26.74 27.451 28.801 28.293 25.91 25.193 26.260 25.309
36 58.652 60.81 59.564 54.652 52.227 48.69 52.556 52.268 52.973
44 39.723 39.37 35.967 42.512 42.111 40.40 43.347 44.456 42.084
WT_1 WT_2 WT_3
27 0.338 0.610 0.583
32 42.181 39.339 42.220
33 0.451 0.366 0.737
34 26.931 28.843 25.977
36 58.707 58.785 57.665
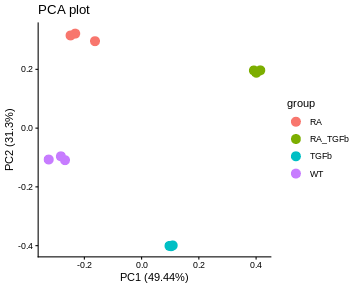
44 41.354 39.583 41.360Before we can proceed, however, we need to do something very important: we need to check that the normalisation methodology we’ve applied has actually worked! One way of doing this is through visualisation. You want to see that the normalisation has (1) removed technical (unwanted) variation, while (2) retaining (i.e. not removing) the biological differences of interest. For example, here’s what our data looks like after normalising for library size and composition:
R
# log transform adjusted CPM values
y <- cpm(dge, log=TRUE)
# PCA plot (nice ggplot version, potentially for publication)
pca <- prcomp(t(y), center=TRUE)
autoplot(pca, data.frame(group=group), col='group', size=4) +
theme_classic() +
ggtitle("PCA plot")
R
# boxplot and RLE plot (simple base R versions; they're generally not for publication)
par(mfcol=c(1,2))
cols.group <- group
levels(cols.group) <- hue_pal()(4)
boxplot(y, col=as.character(cols.group), outline=FALSE, las=2, cex.axis=0.6, main="Boxplots")
RLE <- y - rowMedians(y)
boxplot(RLE, col=as.character(cols.group), outline=FALSE, las=2, cex.axis=0.6, main="RLE plot")
abline(h=0, col="grey20", lwd=3, lty=1)
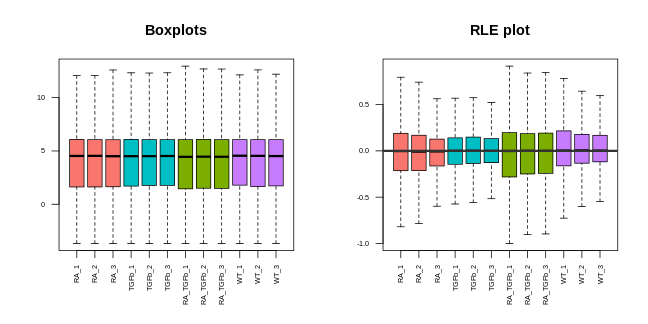
Note that we can now use the cpm function to calculate logged data. The PCA plot looks better: the replicates are clustered more tightly (technical variation has been removed), and the biological groups are more separated (biological differences between groups are maintained, actually improved). Moreover, the boxplots and RLE plot are looking much better: the boxplots are lined up, and the RLE plot medians are centered on zero and the boxes are roughly similar in size.
WARNING!…library size and composition differences aren’t the only kinds of technical differences that can arise between samples:
-
Another way they can arise is when different samples are prepared differently, e.g.
- with different protocols, or
- in different labs, or
- on different dates, or
- by different people, or
- etc.
These differences can lead to so-called “batch effects”. For example, consider these PCA plots of a real data set:
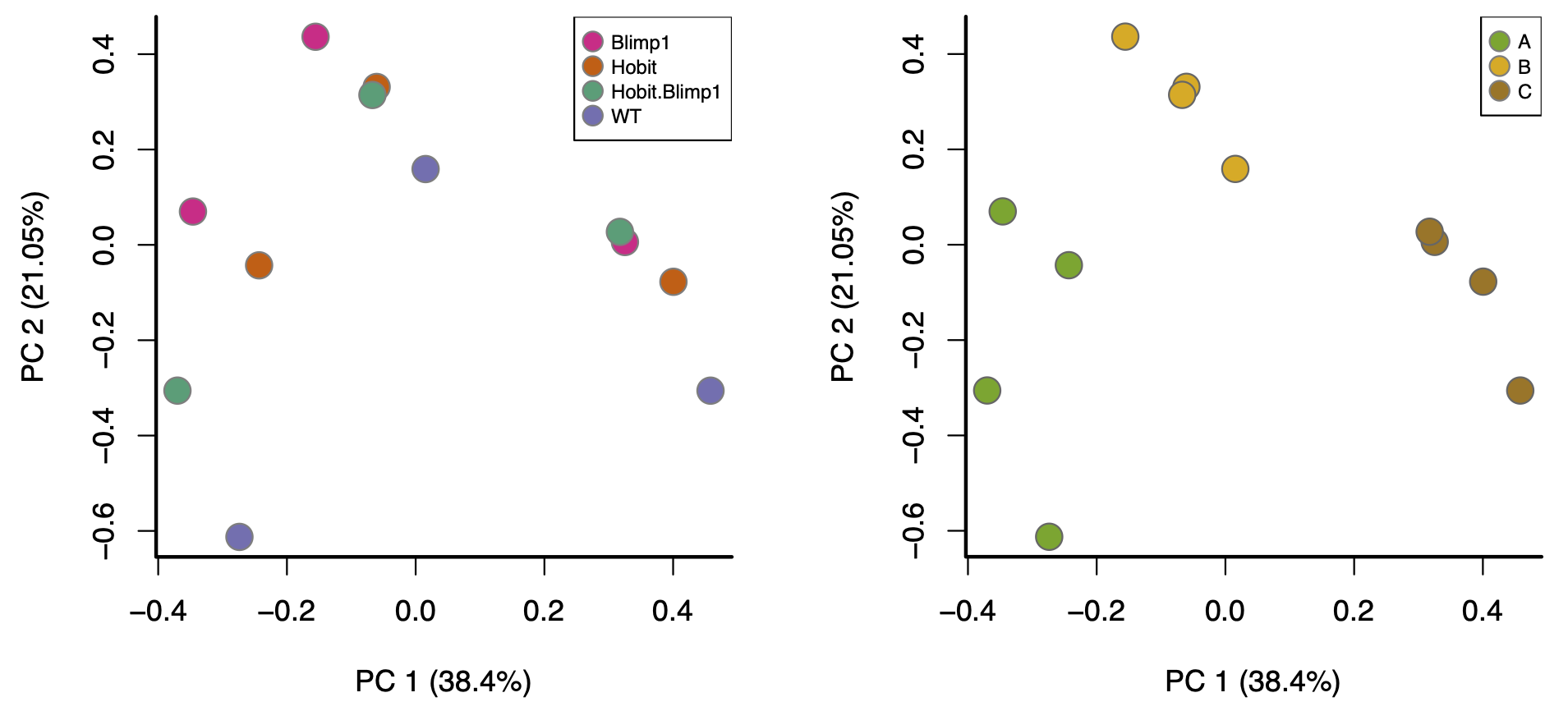
These are both the “same” PCA plot, but one is coloured by biological condition and the other is coloured by batch. The major factor driving separation (along PC1) is batch, not biological condition; consequently, replicates are not clustering by group, and the groups aren’t separating. Batch effects like these can only be corrected with more sophisticated analysis approaches, a topic outside the scope of this workshop.
- Moreover, batch effects aren’t the only way problems can arise (beyond library size and composition). For example, consider this PCA plot of another real data set (coloured by biological condition):
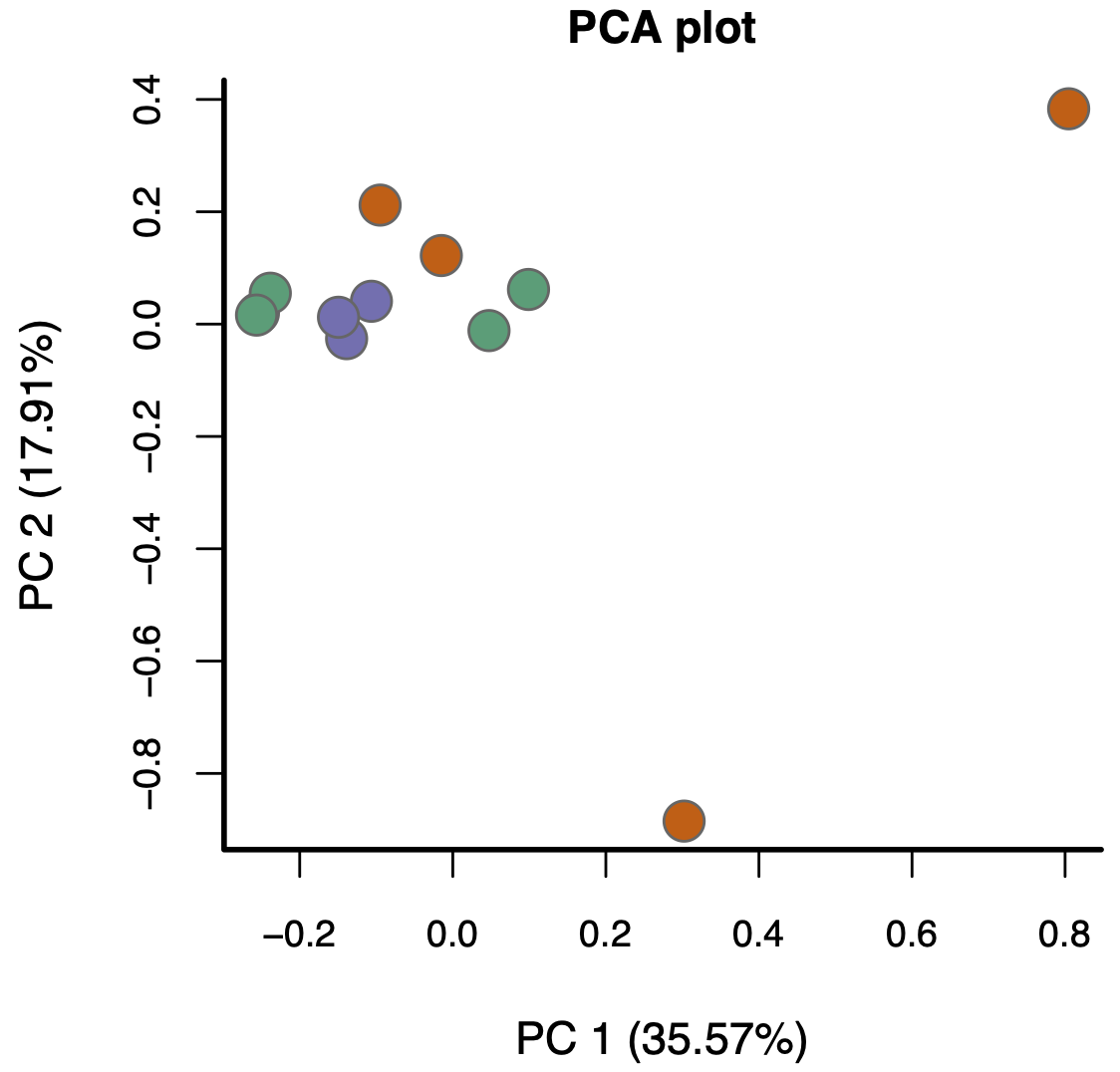
Again, the replicates aren’t really clustering and the groups aren’t really separating. The problem here, however, isn’t batch effects—it’s something much more subtle.
The bottom line is this: if, after normalising for library size and composition, your visualisations don’t look reasonably “good”, in the ways discussed above, the results you’ll get from proceeding with a DE analysis will likely contain missed and/or false discoveries—you’ll likely get rubbish results.
- Filtering lowly expressed genes improves signal-to-noise and reliability of DE results.
- Library size influences count comparisons; larger libraries generally provide more statistical power.
- Visualisation (PCA, boxplots, RLE) is essential to detect technical variation and assess data quality.
- Log transformation of counts stabilises variance and makes visual patterns easier to interpret.
- Normalisation corrects for library size and compositional biases, allowing fair comparison across samples.
- TMM (trimmed mean of M-values) is a common method for normalising RNA-seq data using edgeR.
- Good normalisation removes unwanted technical variation while preserving biological signal.
- Persistent technical effects (e.g. batch effects) require more advanced correction strategies beyond basic normalisation.
Content from Differential expression with limma
Last updated on 2025-11-10 | Edit this page
Overview
Questions
- How does the limma method identify differentially expressed genes?
- Why are linear models used to analyse RNA-seq data?
- What role does empirical Bayes moderation play in improving DE analysis?
- How can we assess whether DE results are trustworthy?
- What is the difference between the limma-trend and limma-voom approaches?
Objectives
- Understand how RNA-seq data can be modelled using linear models in limma.
- Perform DE testing using moderated t-statistics and empirical Bayes.
- Interpret log-fold-changes, p-values, and adjusted p-values (FDR).
- Evaluate DE results with diagnostic plots (SA, MD, p-value histograms).
- Compare and choose between the limma-trend and limma-voom approaches.
Statistical model (for the data)
Let’s remind ourselves of our goal. Look again at the made up table of counts:
We want to answer the question: which genes are DE, i.e. have significantly different levels of expression between groups? For example, does Gene 3 have higher expression in group B? It looks like it does (assuming there’s no library size and composition difference), but there’s also variation. Thus, we need to do some statistics! And for this we’re going to need a statistical model for the data. Let \(Y_{ij}\) be the count for gene \(i\) in sample \(j\):
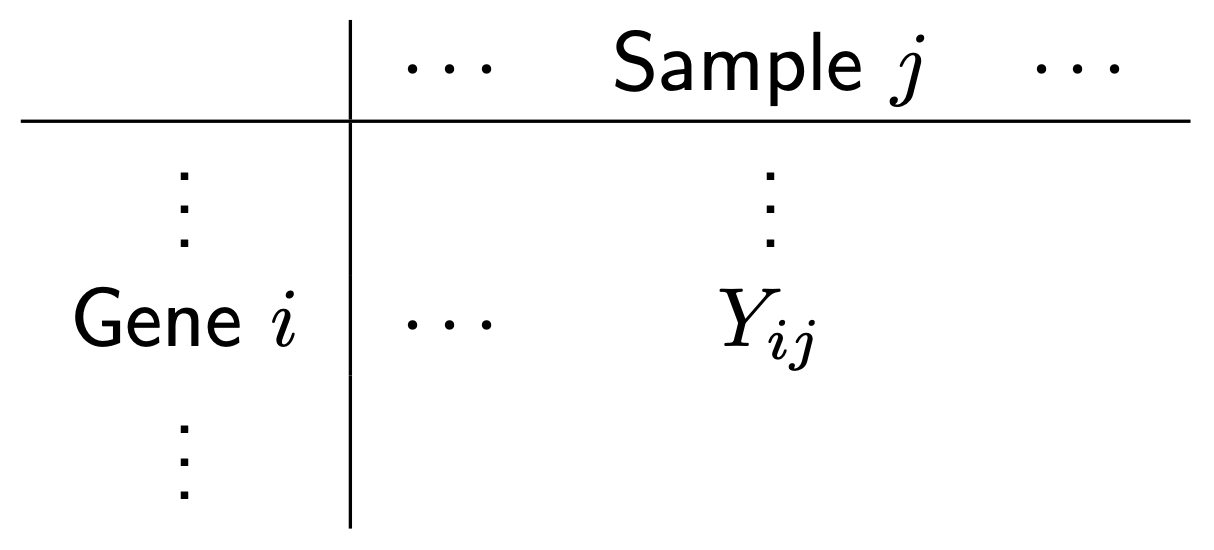
For various reasons (theoretical and empirical), it turns out that a good model for RNA-seq count data (on biological replicates) is the Negative Binomial (NB) distribution: \[ Y_{ij} \sim \text{Negative Bionomial} \] You might have never even heard of this obscure distribution! Remarkably, however, it can shown that log transformed NB count data (or adjusted CPM data) follows, to good approximation, a simple Normal distribution: \[ \log(Y_{ij}) \sim \text{Normal} \] With this in mind, we can distinguish the two main approaches to DE analysis:
- Analyse the counts directly
- Popular methods are:
edgeRandDEseq2 - These use the NB distribution and generalised linear models (GLMs)
- Roughly speaking, these are applicable in all situations (in
contrast to recommendations below)
- Popular methods are:
- Analyse log transformed expression values (more precisely: log
transformed adjusted CPM values)
- The most popular method is
limma, which comes in two flavours:limma-trendandlimma-voom - These use the normal distribution and simple linear models (LMs).
- Recommendations
- Neither flavour is recommended when library sizes are very small (e.g. less than 1M) [or more generally: when the average counts per feature is small]
-
limma-voomin particular is recommended when library sizes are very different (e.g. some libraries have size 2M while others have size 20M).
- The most popular method is
Since the library sizes aren’t too small in our example, we’ll focus
on the limma approach, and since the library sizes aren’t
too different, we’ll focus initially on limma-trend and
return to a discussion of limma-voom later. While methods
that analyse counts directly are more generally applicable, they’re more
difficult to understand conceptually and to apply. Thankfully, however,
the log transformation approach (limma) is applicable to
most RNA-seq data sets.
The first step in our analysis will be to create another container,
called an EList, which will store our log transformed
(adjusted) CPM values and gene annotation:
R
y <- new("EList")
y$E <- cpm(dge, log=TRUE, prior.count=1/2)
y$genes <- dge$genes
Linear model (for the means)
Now that we’ve decided on a model for the data, and corresponding methodology, we need to connect the data to the means for each experimental group. For this, we use a linear model. There’s many ways to talk about and apply linear models—we’ll do it the simplest way possible.
Take any gene, and let \(y_1, y_2, \ldots, y_{12}\) be the 12 log expression observations for that gene. Now let \(y_{1,RA}, y_{2,RA}, y_{3,RA}\) be the three observations for the RA group specifically. We can write \[ \begin{align} y_{1,RA} &= \mu_{RA} + \epsilon_1 \\ y_{2,RA} &= \mu_{RA} + \epsilon_2 \\ y_{3,RA} &= \mu_{RA} + \epsilon_3, \end{align} \] where \(\mu_{RA}\) is the RA group mean and the \(\epsilon\)’s are random errors (i.e. biological variation!). Note that all three observations share the group mean \(\mu_{RA}\); they differ only because of the random errors.
Similarly, we can do this for all 12 observations: \[ \begin{align} y_{1,RA} &= \mu_{RA} + \epsilon_1 \\ y_{2,RA} &= \mu_{RA} + \epsilon_2 \\ y_{3,RA} &= \mu_{RA} + \epsilon_3 \\ y_{4,TGFb} &= \mu_{TGFb} + \epsilon_4 \\ y_{5,TGFb} &= \mu_{TGFb} + \epsilon_5 \\ y_{6,TGFb} &= \mu_{TGFb} + \epsilon_6 \\ y_{7,RA\_TGFb} &= \mu_{RA\_TGFb} + \epsilon_7 \\ y_{8,RA\_TGFb} &= \mu_{RA\_TGFb} + \epsilon_8 \\ y_{9,RA\_TGFb} &= \mu_{RA\_TGFb} + \epsilon_9 \\ y_{10,WT} &= \mu_{WT} + \epsilon_{10} \\ y_{11,WT} &= \mu_{WT} + \epsilon_{11} \\ y_{12,WT} &= \mu_{WT} + \epsilon_{12}. \end{align} \] Now, using some simple high-school matrix-vector notation and algebra, we can write \[ \begin{bmatrix} y_{1,RA} \\ y_{2,RA} \\ y_{3,RA} \\ y_{4,TGFb} \\ y_{5,TGFb} \\ y_{6,TGFb} \\ y_{7,RA\_TGFb} \\ y_{8,RA\_TGFb} \\ y_{9,RA\_TGFb} \\ y_{10,WT} \\ y_{11,WT} \\ y_{12,WT} \end{bmatrix} \quad = \quad \begin{bmatrix} \mu_{RA} + \epsilon_1 \\ \mu_{RA} + \epsilon_2 \\ \mu_{RA} + \epsilon_3 \\ \mu_{TGFb} + \epsilon_4 \\ \mu_{TGFb} + \epsilon_5 \\ \mu_{TGFb} + \epsilon_6 \\ \mu_{RA\_TGFb} + \epsilon_7 \\ \mu_{RA\_TGFb} + \epsilon_8 \\ \mu_{RA\_TGFb} + \epsilon_9 \\ \mu_{WT} + \epsilon_{10} \\ \mu_{WT} + \epsilon_{11} \\ \mu_{WT} + \epsilon_{12} \end{bmatrix} \quad = \quad \begin{bmatrix} 1 & 0 & 0 & 0 \\ 1 & 0 & 0 & 0 \\ 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} \mu_{RA}\\ \mu_{RA\_TGFb}\\ \mu_{TGFb}\\ \mu_{WT} \end{bmatrix} \quad + \quad \begin{bmatrix} \epsilon_1 \\ \epsilon_2 \\ \epsilon_3 \\ \epsilon_4 \\ \epsilon_5 \\ \epsilon_6 \\ \epsilon_7 \\ \epsilon_8 \\ \epsilon_9 \\ \epsilon_{10} \\ \epsilon_{11} \\ \epsilon_{12} \end{bmatrix} \] or, more compactly: \(\mathbf{y} = \mathbf{X} \boldsymbol\beta + \boldsymbol\epsilon\). This is the linear model for our data, and we’ll use the following terminology:
- \(\mathbf{X}\) is called the “design” matrix
- \(\boldsymbol\beta\) is called the vector of coefficients
We’ll fit this (one) model to every gene, which amounts to estimating the coefficient vector \(\boldsymbol\beta\) for each gene, i.e. the group means for every gene!
While the terminology above is important to know, don’t worry if you
didn’t follow all the details of the discussion. The details are there
partly for completeness, but mostly to help demystify design matrices:
they’re just something that connects your data (observed expression
values) to the things of interest, in our case the means of the groups.
The design matrix is easy to make using our group factor
vector:
R
X <- model.matrix(~0 + group) # note the "0": VERY important!
colnames(X) <- levels(group)
X
OUTPUT
RA RA_TGFb TGFb WT
1 1 0 0 0
2 1 0 0 0
3 1 0 0 0
4 0 0 1 0
5 0 0 1 0
6 0 0 1 0
7 0 1 0 0
8 0 1 0 0
9 0 1 0 0
10 0 0 0 1
11 0 0 0 1
12 0 0 0 1
attr(,"assign")
[1] 1 1 1 1
attr(,"contrasts")
attr(,"contrasts")$group
[1] "contr.treatment"Observe, of course, that this is the same as the design matrix above. Fitting the linear model is easy too:
R
fit <- lmFit(y, design=X)
names(fit)
OUTPUT
[1] "coefficients" "rank" "assign" "qr"
[5] "df.residual" "sigma" "cov.coefficients" "stdev.unscaled"
[9] "pivot" "genes" "Amean" "method"
[13] "design" R
head(fit$coefficients)
OUTPUT
RA RA_TGFb TGFb WT
27 -0.412 -0.818 -0.887 -0.960
32 5.422 5.156 5.196 5.366
33 -0.547 -0.510 -1.816 -0.955
34 4.772 4.678 4.790 4.768
36 5.899 5.717 5.695 5.868
44 5.261 5.436 5.381 5.350We’ve arrived at the group means for each gene, but this isn’t what we’re really after: what we really want are differences between the group means—remember: we’re looking for DE genes—or, more precisely, we want differences between the group means for contrasts (i.e. comparisons) of interest. To do this, we construct the contrasts of interest and then fit them. For example, suppose we’re interested in two comparisons: (1) RA vs WT (i.e. the effect of RA), and (2) TGFb vs WT (i.e. the effect of TGFb). The corresponding contrast (matrix) is constructed as follows:
R
CM <- makeContrasts(
RA_WT = RA - WT,
TGFb_WT = TGFb - WT,
levels=X)
CM
OUTPUT
Contrasts
Levels RA_WT TGFb_WT
RA 1 0
RA_TGFb 0 0
TGFb 0 1
WT -1 -1Now, to calculate these contrasts, i.e. to fit them, we do the following:
R
fit2 <- contrasts.fit(fit, contrasts=CM)
head(fit2$coefficients)
OUTPUT
Contrasts
RA_WT TGFb_WT
27 0.5487 0.0731
32 0.0556 -0.1699
33 0.4082 -0.8608
34 0.0038 0.0217
36 0.0314 -0.1726
44 -0.0891 0.0317This has transformed the initial coefficients (i.e. groups means) into the contrasts of interest: the difference in means between the RA and WT groups (column 1) and the difference in means between the TGFb and WT groups (column 2).
Testing for DE
Now that we have our differences in group means for each gene, we want to ask if any of these differences are significantly different from zero (over and above what you might see by random chance). In other words, for each gene we want to statistically test if the means of the two groups are different—more simply: we want to test for DE! To do this, we’ll use the so-called t-test (applied to each gene), whose test statistic looks like this: \[ T = \frac{\bar{y}_{_{A}} - \bar{y}_{_{B}}}{ \sqrt{v}} \] where \(\bar{y}_{_{A}}\) and \(\bar{y}_{_{B}}\) are the means of the two groups being compared, and \(v\) is an estimate of the variance. To test the null hypothesis (that the means are the same), we use the \(t\)-distribution to calculate probabilities about this test statistic (if the chances of seeing certain values of \(T\) are small, this is evidence against the null hypothesis that the group means are the same).
At this point you must be thinking: “why did we do all that linear models stuff if, in the end, we’re just going to use a t-test?” There are at least two reasons. Briefly:
- By using a linear model we’ve actually used all the samples to estimate the variability \(v\) here (a standard t-test would only estimate it from the two groups being compared) and so the estimate is better.
- Linear models are much more powerful than our simple situation suggests: they can be used to easily adjust for things which aren’t of interest but affect the things of interest, e.g. you can make comparisons while adjusting for biological things (e.g. sex) or while adjusting for technical things (e.g. batch), or while adjusting for both!
Hopefully this convinces you that linear models are your friend, but now you must be thinking a different question: “wait a second…we’re going to do t-tests with as little as 2 or 3 observations in each group?…that’s crazy!” Yes, that does seem crazy—there’s barely any information in each group to make a reliable inference about whether the means are different. But this is where the real magic of RNA-seq analysis comes in, the thing that makes it all work: empirical Bayes statistics. The full details are beyond the scope of our discussion, but the rough idea is this: we use a procedure whereby the genes are allowed to share information with each other—this sharing of information between genes makes up for the fact that there isn’t much information within any single gene. This procedure is applied to the gene variances—the \(v\)’s above—which moderates them, making them better estimates, and thus increasing our power to detect DE (other terms for this ‘moderation’ procedure include ‘shrinkage’ or ‘regularization’, terms which you may see in your travels—this powerful technique is used in many places in statistical omics analysis). So, the statistic used to test for DE is actually \[ \widetilde{T} = \frac{\bar{y}_{_{A}} - \bar{y}_{_{B}}}{ \sqrt{ \widetilde{v} }} \] where \(\widetilde{v}\) is the moderated variance; accordingly, \(\widetilde{T}\) is called the “moderated t-statistic”.
That said, testing for DE with the moderated t-statistic is actually easy:
R
fit2 <- eBayes(fit2, trend=TRUE) # "eBayes" means empirical Bayes
names(fit2) # note the addition of "t" (and other empirical Bayes things, which needn't concern us)
OUTPUT
[1] "coefficients" "rank" "assign" "qr"
[5] "df.residual" "sigma" "cov.coefficients" "stdev.unscaled"
[9] "pivot" "genes" "Amean" "method"
[13] "design" "contrasts" "df.prior" "s2.prior"
[17] "var.prior" "proportion" "s2.post" "t"
[21] "df.total" "p.value" "lods" "F"
[25] "F.p.value" NOTE. We’ve specified the function option trend=TRUE
(this isn’t default). This is because one characteristic of RNA-seq data
is that there is a downward trend in variability as a function of the
level of expression—genes with lower levels of expression are more
variable than genes with higher levels of expression (see next section).
The empirical Bayes procedure takes this trend into account.
There’s a fair amount of differential expression—here’s the number of DE genes for each comparison:
R
dt <- decideTests(fit2)
summary(dt)
OUTPUT
RA_WT TGFb_WT
Down 1989 3022
NotSig 10353 8175
Up 1667 2812Some checks
Before we look at the DE results more closely, there’s some things we need to check:
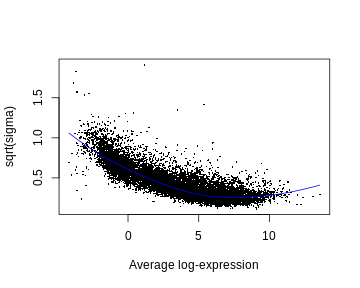
- SA plot. This is a plot of variability (estimated by the linear model) as a function of expression level. It typically has a characteristic shape: it (monotonically) trends downward.
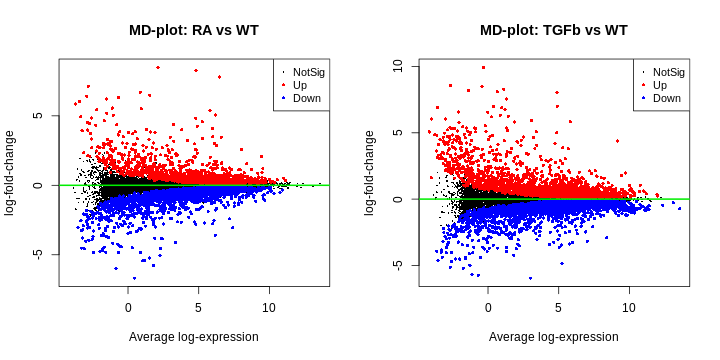
- MD plot (for each comparison). This is simply a plot of log-fold-change (y-axis) and expression level (x-axis) for all genes. The meaning of ‘log-fold-change’ will be discussed below. For now, we note that these plots should look as follows: (1) the ‘cloud’ of data is skewered through the middle, (2) the red/blue dots are on top/bottom, respectively, and in roughly the same proportions (unless you have a reason to think otherwise), and (3) there’s a characteristic funnel shape, thicker to thinner as expression level increases.
- p-value histogram (for each comparison). This is simply a histogram of all the DE hypothesis test p-values (one p-value for each gene). It should look like this: flat, with a possible spike on the far left. The intuitive idea here is simple: a large majority of genes aren’t DE, i.e. the null hypothesis is true for then, and so testing them for DE should just produce p-values that are random noise between 0-1, and thus a the histogram of these p-values should be flat; the possible spike to the far left are p-values from genes which are truly DE.
These are made as follows:
R
plotSA(fit2)
R
par(mfcol=c(1,2))
plotMD(fit2, coef="RA_WT", status=dt[,"RA_WT"], cex=0.6, main="MD-plot: RA vs WT")
abline(h=0, lwd=2, col="green2")
plotMD(fit2, coef="TGFb_WT", status=dt[,"TGFb_WT"], cex=0.6, main="MD-plot: TGFb vs WT")
abline(h=0, lwd=2, col="green2")
R
par(mfcol=c(1,2))
hist(fit2$p.value[,"RA_WT"], col="grey", xlab="p-value", main="p-value histogram: RA vs WT")
hist(fit2$p.value[,"TGFb_WT"], col="grey", xlab="p-value", main="p-value histogram: TGFb vs WT")
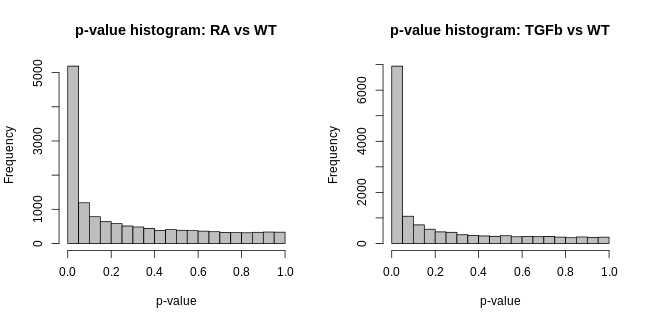
These visualisations look as they should in this case. However, if you produce plots that don’t look reasonably close to these, then something isn’t right. Depending on how bad they look, the results will likely contain missed and/or false discoveries—they’ll be rubbish. The p-value histograms are particularly important. Consider two real examples from different data sets below:
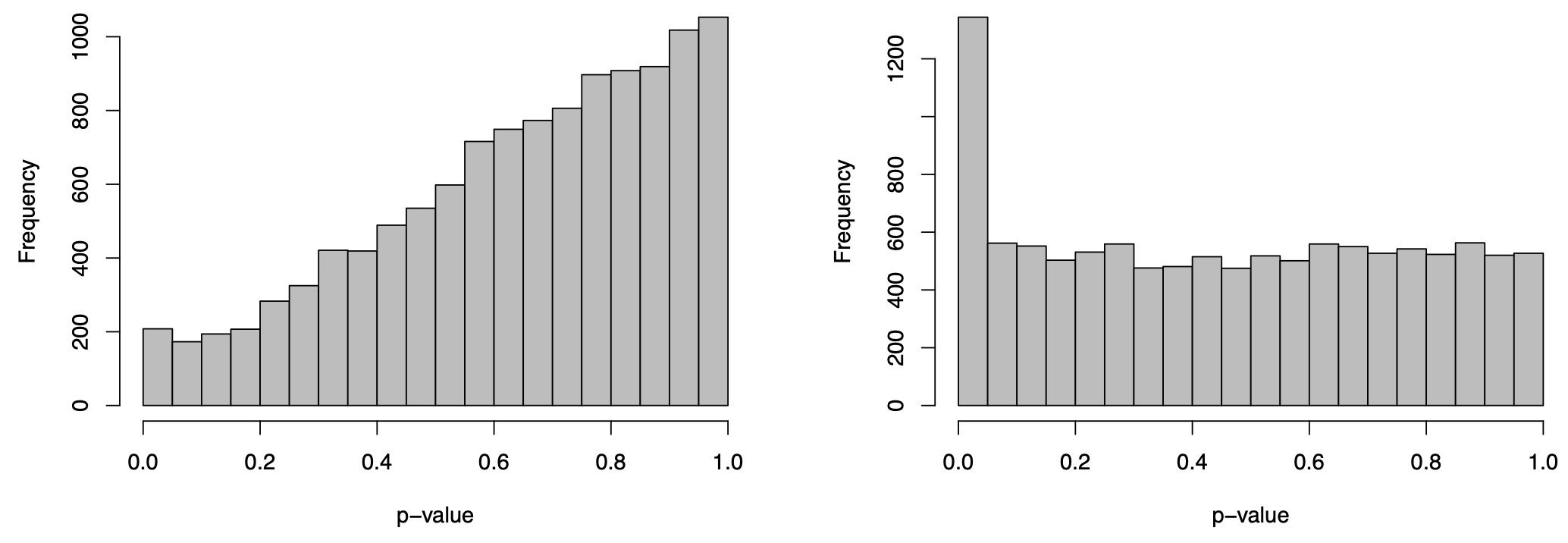
The plot on the right is ideal, i.e. flat with possible spike to the left. The plot on the left is far from ideal. If you produce a plot that looks like this, your results are likely rubbish!
Results
With these checks done, we’re now ready to look at the results. Here’s results for the top genes from each comparison:
R
tab1 <- topTable(fit2, coef="RA_WT", n=Inf)
tab2 <- topTable(fit2, coef="TGFb_WT", n=Inf)
# RA vs WT
head(tab1)
OUTPUT
EnsemblID Symbol logFC AveExpr t P.Value adj.P.Val B
16476 ENSMUSG00000023961 Enpp4 3.37 5.25 48.6 3.76e-16 3.07e-12 25.5
41476 ENSMUSG00000029530 Ccr9 7.79 6.47 48.1 4.39e-16 3.07e-12 25.4
41478 ENSMUSG00000025245 Lztfl1 5.06 6.21 46.2 7.33e-16 3.42e-12 25.1
18334 ENSMUSG00000039982 Dtx4 2.88 6.25 42.8 1.98e-15 6.93e-12 24.4
30887 ENSMUSG00000029468 P2rx7 8.25 4.81 40.4 4.14e-15 1.16e-11 23.9
29165 ENSMUSG00000029093 Sorcs2 8.48 2.12 36.9 1.37e-14 3.19e-11 23.0R
# TGFb vs WT
head(tab2)
OUTPUT
EnsemblID Symbol logFC AveExpr t P.Value adj.P.Val B
17757 ENSMUSG00000024544 Ldlrad4 3.87 5.29 49.1 3.34e-16 4.68e-12 26.4
22483 ENSMUSG00000038400 Pmepa1 2.91 5.11 40.5 4.05e-15 2.84e-11 24.4
6625 ENSMUSG00000020841 Cpd 5.00 4.86 37.6 1.05e-14 4.90e-11 23.7
9268 ENSMUSG00000095079 Igha 8.04 4.88 35.7 2.06e-14 7.13e-11 23.1
14875 ENSMUSG00000022657 Cd96 1.59 8.21 35.1 2.54e-14 7.13e-11 22.9
14967 ENSMUSG00000047293 Gpr15 6.24 1.43 34.5 3.19e-14 7.44e-11 22.7Let’s interpret these results (note: we’ll ignore the “B” column):
- Symbol. These are simply gene symbols.
- AveExpr. The average level of expression for that gene (taken across all samples).
- logFC, i.e. log-fold-change. This is important, but sometimes misunderstood. Here it means the difference between the group means, or more specifically: for the first table logFC = RA group mean - WT group mean; for the second table logFC = TGFb group mean - WT group mean. The reason for the “log” bit in “log-fold-change” is because the means are calculated on a log-scale; the reason for the “fold-change” bit in “log-fold-change” is because a difference of logs is the log of the ratio.
- t. The moderated t-statistic.
- P.Value. The p-value for the hypothesis test of DE obtained using the moderated t-statistic (NOTE: this is typically ignored–see below).
- adj.P.Val. The p-value adjusted for ‘multiple testing’ (typically using the Benjamini-Hochberg method). Usually a gene is inferred/judged to be DE only if adj.P.Val < 0.05.
The distinction between (5) and (6) is particularly important, so let’s say more. Firstly, in our context, we’re doing ~10,000 hypothesis tests, and so the idea of a p-value isn’t particularly useful. To appreciate this, consider the following xkcd comic:

Recall that the p-value is the probability of seeing certain values of our test statistic, assuming the null hypothesis is true, and that we reject the null assumption if the calculated probability is small, say, below 0.05. But, this implies the following: if we were testing 10,000 genes, and the null hypothesis was true for every gene (i.e. there was no DE in the data set), then we’d still reject the null (i.e. infer DE) for ~500 genes—that’s 500 false discoveries! The solution to this problem is to focus on a different idea: the false discovery rate (FDR). This is the proportion of false discoveries of DE amongst all the genes you’ve declared to be DE. This is what the adjusted p-value (adj.P.Val) represents, i.e. if you choose a DE cutoff of adj.P.Val < 0.05 then only 5% of the genes declared DE with this cutoff will be false discoveries.
At this point, one extra way of checking your results is to look at any known control genes relevant to the experiment: positive or negative controls, i.e. genes which should or shouldn’t be DE between conditions, respectively. For example, a positive control for this experiment is Hic1 because RA is known to up-regulate this gene—it should be DE in the RA vs WT comparison, and indeed it is:
R
i <- tab1$Symbol=="Hic1"
tab1[i,]
OUTPUT
EnsemblID Symbol logFC AveExpr t P.Value adj.P.Val B
6572 ENSMUSG00000043099 Hic1 4.84 4.79 32 8.57e-14 1.5e-10 21.5If it turned out this gene wasn’t DE, this would cast some doubt over the validity of the analysis.
Finally, let’s save our results in an Excel spreadsheet!:
R
write.xlsx(tab1, file="../Results/DE_RA-vs-WT.xlsx")
WARNING
Warning in file.create(to[okay]): cannot create file
'../Results/DE_RA-vs-WT.xlsx', reason 'No such file or directory'R
write.xlsx(tab2, file="../Results/DE_TGFb-vs-WT.xlsx")
WARNING
Warning in file.create(to[okay]): cannot create file
'../Results/DE_TGFb-vs-WT.xlsx', reason 'No such file or directory'Two limma approaches: “trend” vs “voom”
Recall that there’s two flavours of limma:
trend and voom. We’ve been using the
trend approach, but now we’ll briefly turn to the
voom approach. Both approaches are essentially the same,
except for one key difference: voom first estimates
“precision weights” (the details are beyond our scope) and incorporates
them into the linear modelling step.
Given you now know the trend approach, the
voom approach is easy to summarise. We do all the same
steps above, right up until before we create an EList, at
which point we proceed as follows:
R
# prepare a voom EList, containing "precision weights" from our DGEList and the same design X above
v <- voom(dge, design=X, plot=FALSE)
# fit linear model (to get group means); "precision weights" will be incorporated
fit.voom <- lmFit(v, design=X)
# fit contrasts using the same contrast matrix CM (for the relevant comparisons)
fit2.voom <- contrasts.fit(fit.voom, contrasts=CM)
# test for DE using empirical Bayes moderated t-statistics
fit2.voom <- eBayes(fit2.voom, trend=FALSE) # NOTE: trend=FALSE (see comments below)
# DE summary and results
dt <- decideTests(fit2.voom)
summary(dt)
OUTPUT
RA_WT TGFb_WT
Down 2037 3160
NotSig 10228 7886
Up 1744 2963R
# top DE genes
topTable(fit2.voom, coef="RA_WT")
OUTPUT
EnsemblID Symbol logFC AveExpr t P.Value adj.P.Val
16476 ENSMUSG00000023961 Enpp4 3.37 5.25 43.0 9.58e-16 1.10e-11
18334 ENSMUSG00000039982 Dtx4 2.88 6.25 41.4 1.57e-15 1.10e-11
3877 ENSMUSG00000089672 Gp49a 3.46 6.60 37.5 5.89e-15 2.06e-11
41478 ENSMUSG00000025245 Lztfl1 5.07 6.21 37.9 5.08e-15 2.06e-11
3878 ENSMUSG00000062593 Lilrb4 3.49 6.00 34.5 1.82e-14 5.11e-11
41476 ENSMUSG00000029530 Ccr9 7.77 6.47 32.3 4.34e-14 1.01e-10
2169 ENSMUSG00000051998 Lax1 -1.42 7.09 -27.1 4.42e-13 6.88e-10
970 ENSMUSG00000026009 Icos -1.62 6.91 -26.8 5.02e-13 7.03e-10
8904 ENSMUSG00000021185 9030617O03Rik -4.14 3.36 -30.4 9.45e-14 1.66e-10
30887 ENSMUSG00000029468 P2rx7 8.23 4.81 31.0 7.52e-14 1.51e-10
B
16476 25.8
18334 25.6
3877 24.7
41478 24.5
3878 23.6
41476 21.5
2169 20.5
970 20.4
8904 20.2
30887 20.1R
topTable(fit2.voom, coef="TGFb_WT")
OUTPUT
EnsemblID Symbol logFC AveExpr t P.Value adj.P.Val B
17757 ENSMUSG00000024544 Ldlrad4 3.87 5.29 50.5 1.14e-16 1.59e-12 27.4
14968 ENSMUSG00000022744 Cldnd1 2.39 5.01 35.3 1.34e-14 4.71e-11 23.9
22483 ENSMUSG00000038400 Pmepa1 2.90 5.11 35.4 1.26e-14 4.71e-11 23.8
6625 ENSMUSG00000020841 Cpd 5.00 4.86 37.4 6.05e-15 4.23e-11 23.8
14875 ENSMUSG00000022657 Cd96 1.59 8.21 34.6 1.76e-14 4.92e-11 23.7
23037 ENSMUSG00000027660 Skil 1.93 7.30 32.0 4.93e-14 1.15e-10 22.7
40680 ENSMUSG00000032420 Nt5e 2.13 7.16 30.9 7.71e-14 1.54e-10 22.3
601 ENSMUSG00000048234 Rnf149 1.79 5.33 30.2 1.04e-13 1.81e-10 21.9
40268 ENSMUSG00000032402 Smad3 -1.76 5.76 -29.7 1.30e-13 2.02e-10 21.7
1145 ENSMUSG00000026192 Atic -1.04 6.40 -27.1 4.30e-13 6.02e-10 20.5The results have the same interpretations as before, and we can also
do the same checks as before (i.e. MD plots, p-value histograms, control
genes) except that instead of checking an SA plot, we check the voom
‘mean-variance’ trend plot produced automatically when
plot=TRUE is specified in the voom function.
Two important comments:
- We specified
trend=FALSEin theeBayesDE testing step. This is because the voom “precision weights” actually remove the trend in variability noted earlier, and so this step doesn’t need to use the ‘trend’ anymore. -
voomis recommended when the library sizes are very different (e.g. some libraries have size 2M while others have size 20M) because the “precision weights” are able to take these differences in library sizes into account.
The library sizes aren’t very different in our example and so both
limma approaches give essentially the same DE genes, as can
be seen here:
R
# DE results
dt.trend <- decideTests(fit2)
dt.voom <- decideTests(fit2.voom)
# venn diagram comparisons
df1 <- cbind(dt.trend[,"RA_WT"], dt.voom[,"RA_WT"])
df2 <- cbind(dt.trend[,"TGFb_WT"], dt.voom[,"TGFb_WT"])
par(mfcol=c(1,2))
vennDiagram(df1,
main="RA vs WT",
names=c("trend","voom"),
include=c("up","down"),
counts.col=c("red3","blue3"),
circle.col=c("purple","turquoise"))
vennDiagram(df2,
main="TGFb vs WT",
names=c("trend","voom"),
include=c("up","down"),
counts.col=c("red3","blue3"),
circle.col=c("purple","turquoise"))
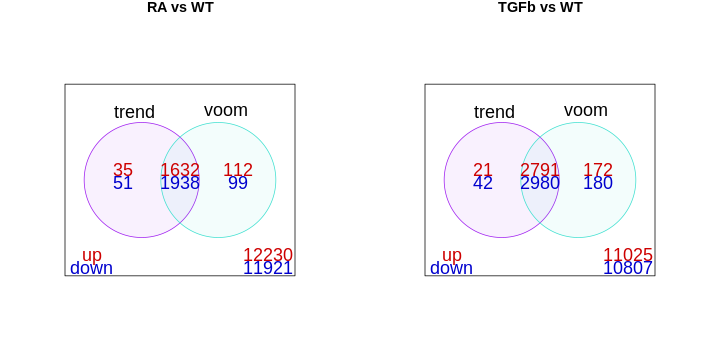
- RNA-seq data can be modelled with linear models after log transformation.
- The limma workflow estimates group means and contrasts, then tests for DE.
- Empirical Bayes moderation stabilises variances, improving reliability.
- Adjusted p-values (FDR) control false discoveries across many tests.
- limma-trend and limma-voom give similar results unless library sizes differ greatly.
Content from Summary and exercise
Last updated on 2025-11-10 | Edit this page
Overview
Questions
- How can we summarise the key steps in an RNA-seq differential expression workflow?
- When should we use limma-trend versus limma-voom?
- How can we visualise and interpret DE results?
- What plots help communicate DE findings effectively?
- Where can we find RNA-seq count data to practise these analyses?
Objectives
- Consolidate the complete RNA-seq DE workflow from filtering to visualisation.
- Apply both limma-trend and limma-voom to new comparisons independently.
- Generate and interpret volcano, MD, and heatmap plots.
- Recognise reliable sources for public RNA-seq count data.
- Gain confidence reproducing and extending DE analyses.
Let’s summarise by putting the key analysis code together with comments (for the RA vs WT comparison). Here’s the preliminaries etc.:
R
# organise data into a DGEList
tab <- read.table("data/GSE232852_CountsTable.txt", header=TRUE)
annotation <- tab[,c(1,2)]
counts <- tab[,-c(1,2)]
dge <- DGEList(counts=counts, genes=annotation)
# sample info and group vector
samples <- colnames(tab)[-c(1,2)]
group <- c(rep("RA",3), rep("TGFb",3), rep("RA_TGFb",3), rep("WT",3))
info <- data.frame(samples, group)
group <- factor(info$group)
# filter for low expression
i <- filterByExpr(dge, group=group)
dge <- dge[i,,keep.lib.size=FALSE]
# check library sizes
lib.size.millons <- colSums(dge$counts) / 1e6
barplot(lib.size.millons, las=2, cex.names=0.8, main="Library size (millons)")
abline(h=20, lwd=2, col="red2")
# visualisation: raw data
y <- log2(dge$counts + 1/2)
pca <- prcomp(t(y), center=TRUE)
autoplot(pca, data.frame(group=group), col='group', size=4) +
theme_classic() +
ggtitle("PCA plot")
cols.group <- group
levels(cols.group) <- hue_pal()(4)
boxplot(y, col=as.character(cols.group), outline=FALSE, las=2, cex.axis=0.7, main="Boxplots")
RLE <- y - rowMedians(y)
boxplot(RLE, col=as.character(cols.group), outline=FALSE, las=2, cex.axis=0.7, main="RLE plot")
abline(h=0, col="grey20", lwd=3, lty=1)
# normalise for library size and composition
dge <- calcNormFactors(dge, method="TMM")
y <- cpm(dge, log=TRUE)
# visualisation: normalised data
pca <- prcomp(t(y), center=TRUE)
autoplot(pca, data.frame(group=group), col='group', size=4) +
theme_classic() +
ggtitle("PCA plot")
cols.group <- group
levels(cols.group) <- hue_pal()(4)
boxplot(y, col=as.character(cols.group), outline=FALSE, las=2, cex.axis=0.5, main="Boxplots")
RLE <- y - rowMedians(y)
boxplot(RLE, col=as.character(cols.group), outline=FALSE, las=2, cex.axis=0.5, main="RLE plot")
abline(h=0, col="grey20", lwd=3, lty=1)
If the library sizes aren’t too different, we proceed with
limma-trend:
R
# organise EList
y <- new("EList")
y$E <- cpm(dge, log=TRUE)
y$genes <- dge$genes
# design matrix
X <- model.matrix(~0 + group)
colnames(X) <- levels(group)
# fit linear model (to get group means)
fit <- lmFit(y, design=X)
# make contrasts
CM <- makeContrasts(
RA_WT = RA - WT,
TGFb_WT = TGFb - WT,
levels=X)
# fit contrasts
fit2 <- contrasts.fit(fit, contrasts=CM)
# test for DE
fit2 <- eBayes(fit2, trend=TRUE)
# some checks
dt <- decideTests(fit2)
plotSA(fit2) # SA plot
plotMD(fit2, coef="RA_WT", status=dt[,"RA_WT"], cex=0.6, main="MD-plot: RA vs WT") # MD plot
abline(h=0, lwd=2, col="green2")
hist(fit2$p.value[,"RA_WT"], col="grey", xlab="p-value", main="p-value histogram: RA vs WT") # p-value hist
# DE results
tab <- topTable(fit2, coef="RA_WT", n=Inf)
write.xlsx(tab, file="../Results/DE_limma-trend_RA-vs-WT.xlsx")
If the library sizes are very different, proceed with
limma-voom:
R
# organise voom EList
v <- voom(dge, design=X, plot=TRUE) # same X as above
# fit linear model (to get group means)
fit.voom <- lmFit(v, design=X)
# fit contrasts
fit2.voom <- contrasts.fit(fit.voom, contrasts=CM) # same CM as above
# test for DE
fit2.voom <- eBayes(fit2.voom, trend=FALSE) # NOTE: trend=FALSE
# some checks
dt <- decideTests(fit2.voom)
plotMD(fit2.voom, coef="RA_WT", status=dt[,"RA_WT"], cex=0.6, main="MD-plot: RA vs WT") # MD plot
abline(h=0, lwd=2, col="green2")
hist(fit2$p.value[,"RA_WT"], col="grey", xlab="p-value", main="p-value histogram: RA vs WT") # p-value hist
# DE results
tab <- topTable(fit2.voom, coef="RA_WT", n=Inf)
write.xlsx(tab, file="../Results/DE_limma-voom_RA-vs-WT.xlsx")
To reinforce what you’ve learnt, try your hand at finding DE results for the RA+TGFb vs WT comparison using both limma approaches.
Solution:
R
# new contrast matrix
CM2 <- makeContrasts(
RA_WT = RA - WT,
TGFb_WT = TGFb - WT,
RA.TGFb_WT = RA_TGFb - WT, # new comparison
levels=X)
# limma-trend
fit2 <- contrasts.fit(fit, contrasts=CM2)
fit2 <- eBayes(fit2, trend=TRUE)
dt <- decideTests(fit2)
summary(dt)
tab <- topTable(fit2, coef="RA.TGFb_WT", n=Inf)
write.xlsx(tab, file="../Results/DE_limma-trend_RA.TGFb_WT.xlsx")
# limma-voom
fit2.voom <- contrasts.fit(fit.voom, contrasts=CM2)
fit2.voom <- eBayes(fit2.voom, trend=FALSE)
dt <- decideTests(fit2.voom)
summary(dt)
tab <- topTable(fit2.voom, coef="RA.TGFb_WT", n=Inf)
write.xlsx(tab, file="../Results/DE_limma-voom_RA.TGFb_WT.xlsx")
Visualisation of results
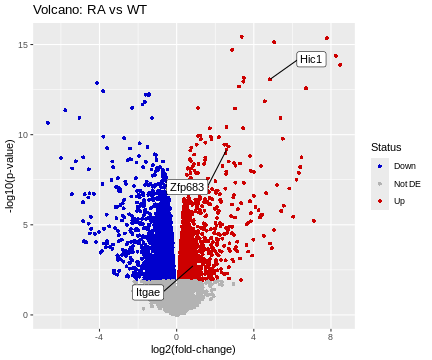
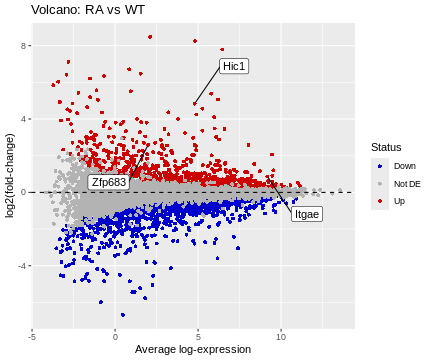
There are several common ways to visualise DE results, e.g. volcano plots, MD plots (already used for checking above but made nicer here), and heatmaps. Let’s produce basic examples of each, for the RA vs WT comparison.
R
# organize data frame for volcano and MD plots
tab <- topTable(fit2, coef="RA_WT", n=Inf)
logFC <- tab$logFC
p.value <- tab$P.Value
A <- tab$AveExpr
Gene <- tab$Symbol
Status <- rep("Not DE", nrow(tab))
Status[tab$logFC>0 & tab$adj.P.Val<0.05] <- "Up"
Status[tab$logFC<0 & tab$adj.P.Val<0.05] <- "Down" # table(Status)
df <- data.frame(logFC, p.value, A, Gene, Status)
# prepare some annotation
genes <- c("Hic1","Itgae","Zfp683")
i <- match(genes, df$Gene)
HL <- df[i,]
# basic volcano plot
ggplot(data=df, aes(x=logFC, y=-log10(p.value))) +
geom_point(shape=16, aes(color=Status)) +
scale_color_manual(values=c("blue3","grey70","red3")) +
geom_label_repel(data=HL, aes(label=Gene), box.padding=2) +
labs(title="Volcano: RA vs WT", x="log2(fold-change)", y="-log10(p-value)")
R
# basic MD plot
ggplot(data=df, aes(x=A, y=logFC)) +
geom_point(shape=16, aes(color=Status)) +
scale_color_manual(values=c("blue3","grey70","red3")) +
geom_hline(yintercept=0, linetype=2, colour="black") +
geom_label_repel(data=HL, aes(label=Gene), box.padding=2) +
labs(title="Volcano: RA vs WT", x="Average log-expression", y="log2(fold-change)")
R
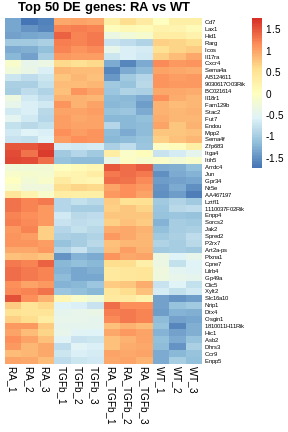
# organize data frame for heatmap
top.genes <- tab[1:50,]$Symbol
df <- y$E
rownames(df) <- y$genes$Symbol
df <- df[top.genes,]
# basic heatmap
pheatmap(
df,
border_color=NA,
scale="row",
cluster_rows=TRUE,
cluster_cols=FALSE,
treeheight_row=0,
main="Top 50 DE genes: RA vs WT",
fontsize_row=6)
Getting data
Now that you have some basic analysis skills, you’ll want to get your hands on some data, e.g. publicly available RNA-seq counts tables. As we’ve seen, one place to get data is Gene Expression Omnibus (GEO). But, GEO can be hit-and-miss: sometimes counts tables are available as supplementary files (as we saw), but sometimes they’re not. Although, sometimes there are other ways of getting counts tables on GEO. It’s really a bit of a mess—you just need to get on there and try your luck.
Thankfully, there are alternatives. For example, for human and mouse data, GREIN is a real gem: its search interface is clear and simple to use and the counts data and sample information is uniformly pre-packaged and ready for easy download. Check it out.
And have fun!
- The full DE workflow combines filtering, normalisation, modelling, and testing.
- limma-trend and limma-voom differ mainly in handling library size variability.
- Visualisations such as volcano plots, MD plots, and heatmaps summarise DE results clearly.
- Public repositories like GEO and GREIN provide accessible RNA-seq count data.
- Mastering reproducible code structure ensures robust and transparent RNA-seq analysis.